As working in a leader role of a data science company, I would like to share my experience in managing different projects under different scales across industries. It could be concluded by one single word
-
Iteration
There is only one single project management approach being employed by our team. For this approach, it helps me with a track record on data warehouse, business intelligence, big data, data mining and now data science projects for around 15 years.

What is the Iteration Project management approach?
For the definition of Iteration Project Management Approach, there are many minor versions on the discussion. In general speaking, this approach is to split the development of the project (big data / data science platform at here) into sequences of repeated cycles (iterations). Each iteration is issued a particular time period.
For the approach being used in companies under my management, which are referencing the approaches from different US software vendors. There are 8 different steps in each iteration and they are:
- Scope – define your business problem or specific area of interest
- Plan – determine the resources involved and estimate the time line
- Manage – manage the iteration, scope, schedule, costs, quality, human resources, communication, risk and procurement throughout the whole cycle.
- Analyze – identify and measure the related business operations and data available within the scope.
- Design – produce drawing on the system architecture, related user interface, report layouts, dashboards, etc.
- Construct – code the solutions and use tools to produce the answer pinpoint to the scope and plan.
- Test – test your solutions in different angles like functional test, stress test and tests on data accuracy, etc.
- Deploy – release your tested version of software or data analytics functions to users as live production.
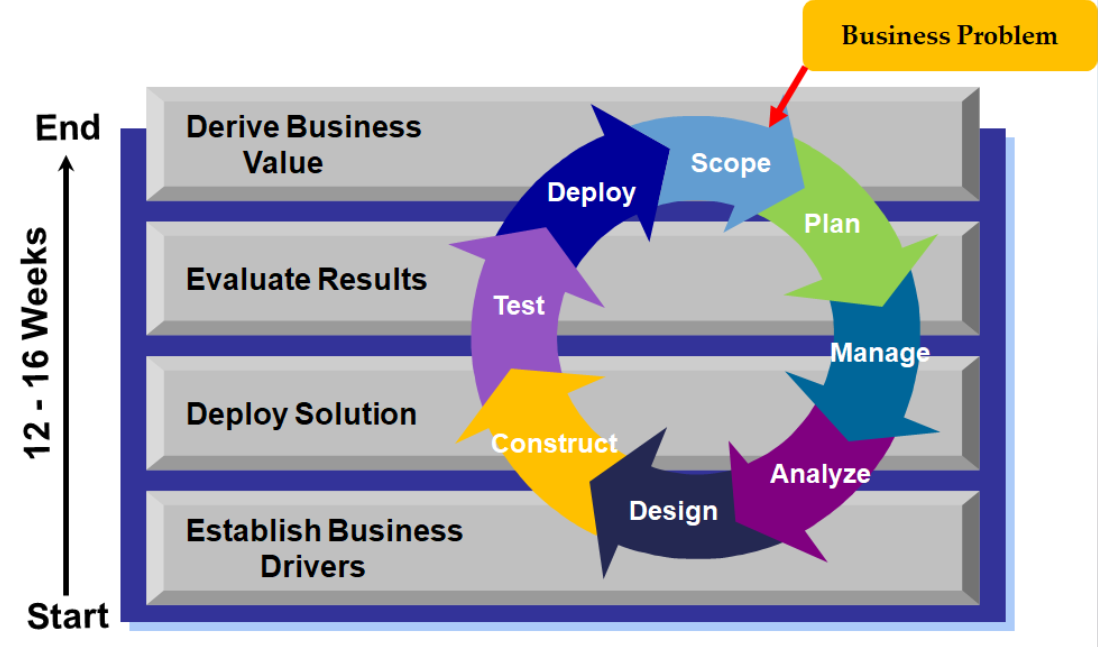
However, after one iteration is complete, there should be corresponding review from business users and/or management to see whether there is another iteration to refine the first iteration in a particular area.
What are the benefits for this approach?
There are 4 main fruitful facts being brought by the iterations:
- Client Involvement – clients’ participations are being encouraged with direct feedback at different stages. So, the risk of miscommunication is being minimized.
- Favour Evolution – allows space for evolving ideas during the whole cycle instead of only being possible to react until the testing phase.
- Risk Assessment – allows risk identification and mitigation early in the development to avoid problems being discovered near the project deadline.
- Rapid Delivery – allows team members dedicated their focus to deliver on time and within the scope. Also, the testing is being carried just after the design and implementation. So, the chance of serious problem is being avoided.
Where areas should be best-fit for Iterative Project Management?
Personally, there are a number of situations fit for the Iteration approach. The most suitable situation is data analytics projects. It’s because business user involvement is one of the key of success. Also, there are some software / applications with rapid delivery. Finally, anther situation nowadays is digital marketing with lots of response directly from the audience. There are lots of possible adjustment during a marketing events being published or based on the feedback from direct custmers.
Conclusion
The business environment is always changing and leading new development and/or refinement with current analytic platform including data warehouse, data lake, etc. In my opinion, there is no alternative to pick any other project management approach in the world of data science.
Samuel Sum
Data Science Evangelist (CDS, SDi)
Vice President (AS)