Vendors are always saying that Data Warehouses are legacy data management platforms which should be replaced by data lakes (or even worse situation as Hadoop to replace data warehouse). In this article, I would like to share my opinion on data warehouse and data lake by the team experiences.
Unfortunately, vendors position data lakes as a complete replacement for data warehouse and as critical elements of analytical infrastructure for collecting mainly internal data and some external one. First of all, there is no “golden” standard of data lake. Different people may draw the data lake picture a bit different. Also, the data lake technology is still not mature enough compared to the stable data warehouse technologies for more than 20 years.
Figure 1: A complete picture of an Enterprise Data Warehouse
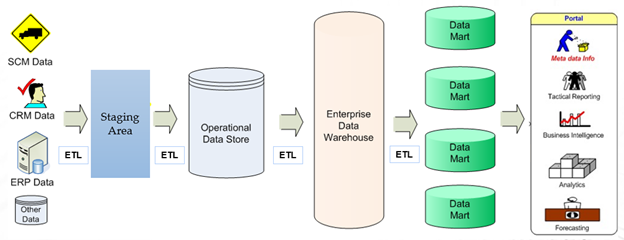
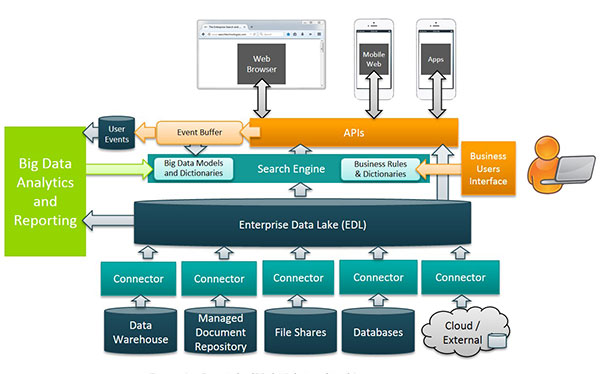
Figure 2: A complete picture of the data lake
In order to understand the difference between data lake and data warehouse, I would like to have the table below for a quick comparison:
| Data Lake | Data Warehouse | |
| Data Structure | Raw | Processed |
| Purpose of Data | Not Yet Determined | Currently in use |
| Users | Data Scientists | Business Professionals / Management |
| Accessibility | Highly accessible and quick to update | More difficult & costly to make changes; focused on easy to read |
| Storage | Data lakes design for low-cost storage | Usually High-end storage like SAN |
| Security | Offers less control | Allow better control with relational database |
| Types of Data | Unstructured, semi-structured and structured | Mostly in tabular form & structure |
| Schema | No predefined schema (schema on reading) | Predefined such as Star-Schema (schema as writing) |
| Data Processing | Fast ingestion of new data | Time consuming when adding new data |
| Data Granularity | Data at a low level of detail or granularity | Data at summary or aggregated level of detail |
| Tool | Hadoop / Map Reduce | Relational Database with or without ETL tools |

For further details, items in the table will be discussed below.
Data Structure
In Data Lake, it is basically raw data being duplicated from different data sources into this big repository for linking one another with some business keys. So, it is not easy to read / filter / sort data in terabytes scale and not instantly read by business user directly and easily. Well, you can’t expect your Tableau, Cognos, Qlik to read the full set of unprocessed data. The best way for data scientists to use this big thing is aimed for machine learning due to the volume of “raw material” to learn.
Purpose of Data
For the data lake, sub-sets of data may still as “dark data” because the purpose of storing is still not yet defined. However, some of data sets are aimed to collect for further processing and analysis in future. For data warehouse, all data including its metadata should be well defined and always ready for reports, dashboard and data mining.
Users
With the well-defined and well-organized data, business professionals and managers could use the data warehouse data directly with their knowledge of business operation. However, the raw data is not expected to be used outside those people highly skillful in handling data. It is not expected your IT department knows how to use the data and they are those only providing the infrastructure.
Accessibility
There are several factors to be considered here:
- Flexibility & Security
- Read VS Write data
- Data Security
For the data lake, everything is available and only a few data scientists should able to access. For the data warehouse, security will be set into detailed level like row & column level security.
For reading data, data warehouse should be response in a very short time with Star Schema, column-based tables, etc. However, the cost of updating data warehouse is much higher than reading it. From the figure 2, additional rules and application are being developed for the access of other systems for retrieval of data and some data driven actions could be applied. When retrieving data from data lake, it depends on the scope of the retrieval and it could burn all system resources when joining all data together.
There is another big topic about the security of data. It is etherical for data scientists and/or business professional to protect the personal data privacy and confidential information. Also, it is important for the technical team to introduce further protection like masking, encryption, etc.
Storage
As data lake is mainly using Hadoop for storing data with a comparatively lower storage cost for the data warehouse (SAN). The license fee is in general cheaper for getting Hadoop solutions than relational database system (RDBMS). However, there are more projects moving to Open Source solutions for both Hadoop and Data Warehouse. I am helping clients to migrate Oracle databases to MariaDB AX and TX and unstructured data to Apache Hadoop.
Security
Data Warehouse is leading comprehensive security down to column or row level. Also, there are lots of different tools developed like encryption, masking, Access Audit Log, etc. Big Data security is mature on the platform protection and never down to single record level. For security handling, it is common to do masking to avoid data leakage.
Types of Data
Data lake is aimed to store all types of data from unstructured to structured data. For data warehouse, it is only structured data structure available.
Schema
For Data Lake, it is the data schema and structure as the original data source without any transformation.
Data Processing
Fast Ingestion is commonly used in data lake. However, ETL is the primary method in Data Warehouse and taking time to process. For Real-time data warehouse, Change Data Capture (CDC) tools will be used like those by IBM, Informatica or Talend.
Data Granularity
All details should be available in the data lake. However, it is expected data being summarized in the data warehouse.
Tools
Apart from the difference between Hadoop and RDBMS, there are a number of tools being used in the data environment. For ETL tool nowadays, they should have the capability to handle Big Data like generating Spark.
My Suggested Approach for a Data Lake
There is no golden standard for data lake up to this moment. However, I think the Data Virtualization may take a vital role for the data lake due to lots of different types of data. Data virtualization tool could link up the relationships between NoSQL database, data warehouse and other database sources with a logical view. This logical view is able to be connected as a normal data source for easy exploration for data scientists. Once there is any important finding, it is possible to expand the data warehouse to feed the valuable data for regular and further analytics.
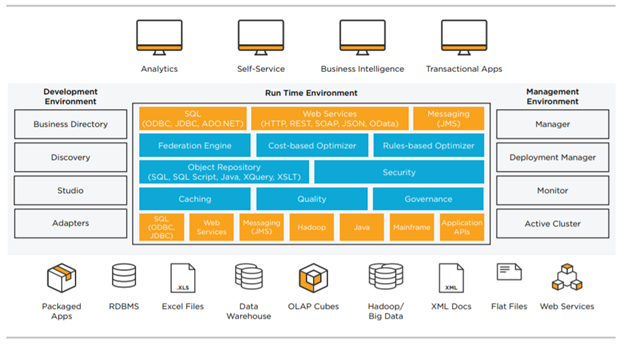
SAP Hana is an example with Data Virtualization, ELT and ETL in one box. However, it is important to highlight the TIBCO Data Virtualization as one of the leaders in the industry. It is still a good idea to use TIBCO Virtualization with other ETL tools like IBM DataStage, Talend, etc. for building your own complete solution.
Figure 3: SAP Hana Environment
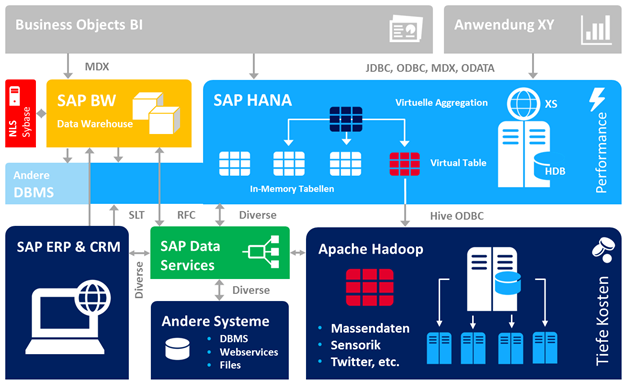
Figure 4: TIBCO Virtualization Module
At this point, you may ask which is the best solution. Personally, it is better to pick up tools with higher flexibility and avoid single vendor to dominate the whole corporate environment to prevent future robbery by a single vendor.
However, there is only 1 free-of-charge choice by Apache Foundation called Apache Drill for Hadoop & NoSQL only (no relational database). It is still worth to try. For paid data virtualization, you should check with the performance, number of data connectors, technical support service quality, pricing and local partner / vendor implementation ability – better to have extensive architecture experiences on database, data warehouse and hadoop.
Conclusion
In a nutshell, data warehouse is still leading its important role in the world of analytics. Moreover, it is important to understand data lake before making any further investments. Data lake maintenance is very costly by replication more & more data overtime.
If you have the needs with a data lake with all available, you should go ahead by implementation in phases. Moreover, Data Virtualization tool could be valuable for connecting the data relationship across different areas of the data lake for fast data access. In the long-run, you may consider additional data integration jobs for such situation – by enriching the data warehouse (feeding with unstructured data or other sources).
Samuel Sum
Data Science Evangelist (CDS, SDi)
Vice President (AS)