In the past month, I have made a number of research and testing on different data science technology including on-premise and cloud solutions. They are:
- Google BigQuery, Cloud Storage, Airflow
- Qilk Sense, Data Streaming (CDC), Data Warehouse Automation, Data Lake Creation
- Debezium CDC
- EnterpriseDB, GaussDB (by Huawei)
In the coming future, I will share some promising service providers or vendors. Personally, I have no financial benefits from any of these suppliers. In this article, I will focus on the Google cloud services for building a data repository or a data lake in small scale. For this case, it is for storing commodity data including both structured and unstructured data – including data from trading system, web logs, crawling weather data, etc.
In the diagram below, it is the high level design for one of my real project with the team of SDI.
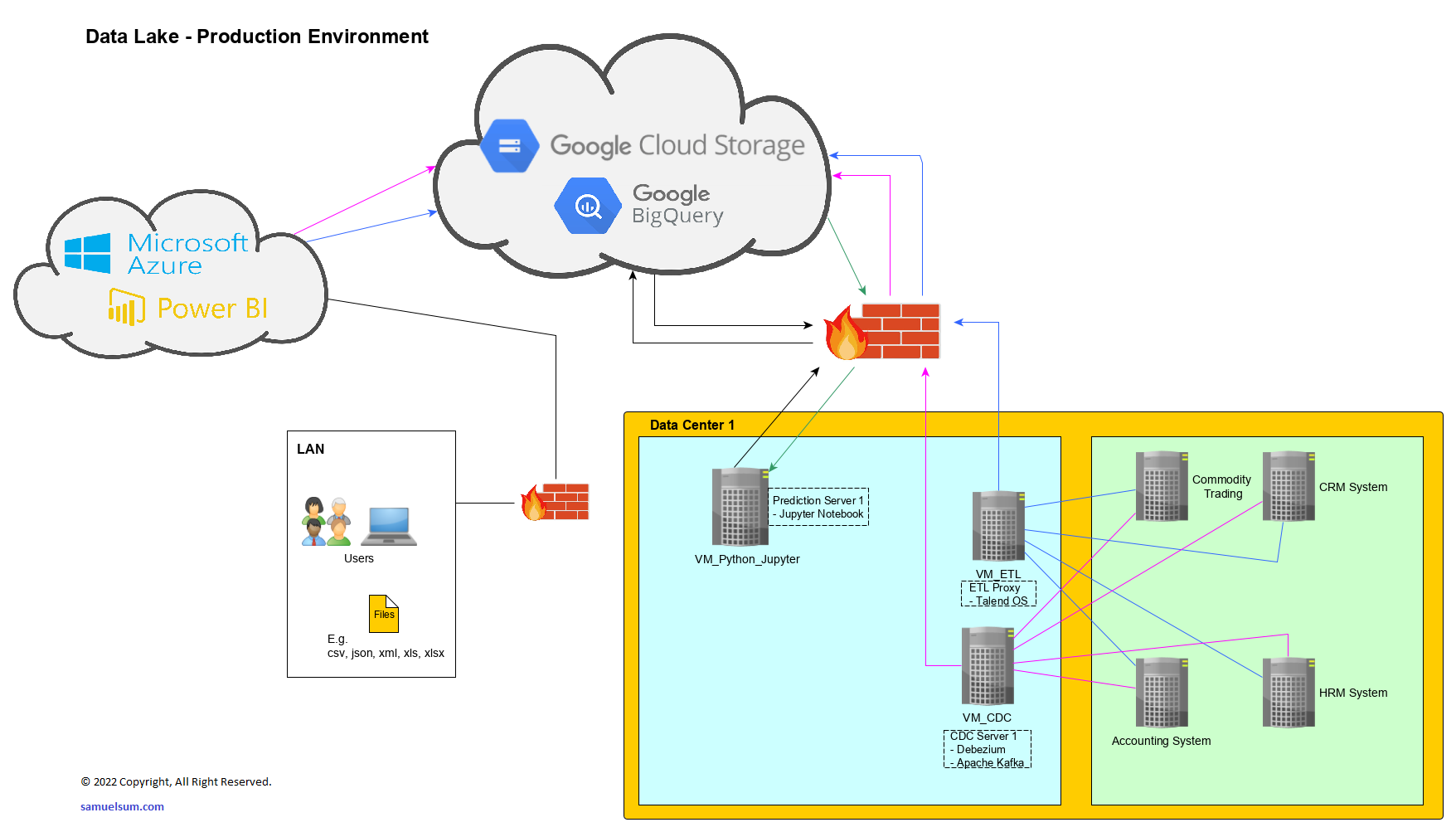
You may have lots of questions for the solution as a mixture of cloud and on-premises (data centre). The major reason is the cost of taking Airflow possibly costing at US$100,000 a year for data volume being used.

Let’s see the tool selection and then the solution explained.
Tool Selection
Google Big Query
There are lots of services for a database as a service from AWS, Microsoft Azure, TenCent Cloud, AliCloud, etc. I pick this for a number of reason:
- Columnar, NoSQL database – very fast in querying data for analysis
- One of the lowest cost service across cloud service providers
- Data-at-rest, table, column level encryption
- being used by HSBC (a banking gaint) for their data warehouse. NOTE: the security audit is passed by Hong Kong Monetary Authority.
Google Cloud Storage
In this case, it is mainly for storage of files and due to the Google Big Query being chosen. Another concern is that there is a file size limit of 5GB per file in AWS. If you’re seeking for the object storage features, it is better to go for AWS S3.
Microsoft PowerBI PRO (Cloud)
As the users are familar with PowerBI, they would like to choose it as the data visualization tool for data analysis. Personally, all BI tools are providing similar functions and it is better to leave it choosing by users.
Then, the following items are running on-premises – VMs located at a data centre. These VMs are running on VMWare and attached to SSD storage for speed.
Talend Open Studio
Talend is one of the best ETL solution. Even my favourite is IBM DataStage, I pick Talend Open Studio as a free tool with enough features for this case. There are some general benefits for having an ETL tool (just like others like IBM DataStage, Infomatica, etc.)
- no/low coding for reducing developer costs
- less error rates due to standardized Java coding generation by workflow
- large community support
Apache Kafka / Debezium CDC
They are being used together for data streaming and replication. In this use-case, they are require real-time data streaming for data analytics (mini batch predictions). It is required the Debezium CDC to capture the source database log and reflect the changes via Kafka replication as the data backbone.
Jupyter Notebook
We are using it with Python. The Jupyter Notebook with Python is the most popular predictive analysis tools in the world. For picking Jupyter Notebook, there are different functions being used.
- Predictive Analysis (such as: commodity pricing trend)
- Automated Portfolio Management (machine learning with tensorflow)
It is comparatively easier to find the corresponding technical people to support. Programmers are easily found but not data engineers and data scientists.
Running Costs
The total spending should be acceptable for many small business.
Data Centre: US$6,000 / year
Google: US$15,000 / year (due to the storage size and usage)
PowerBI: US$2,400 / year (20 users)
Total: US$23,400 / year
Solution
Here is the solution diagram.
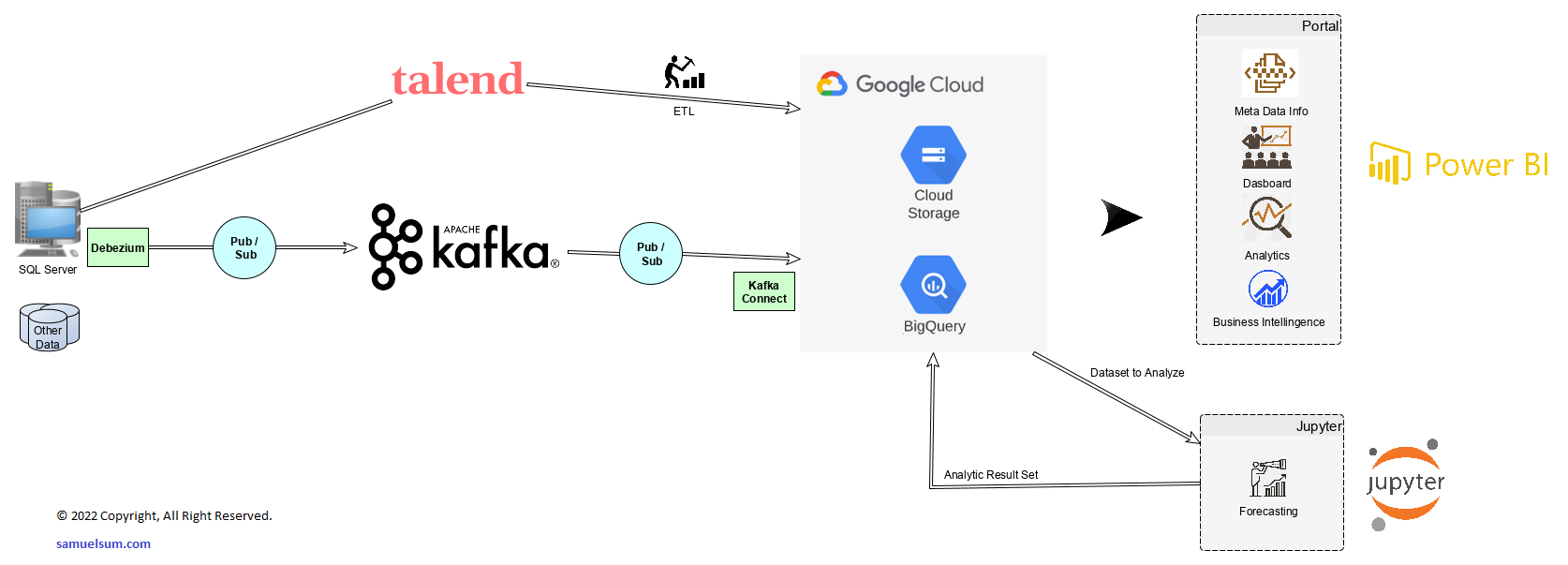
Structured data from different data sources like trading system will be extracted by Talend Open Studio. Then, the data is being transformed and loaded by both Talend Open Studio and the SQL in BigQuery depending on the business requirements and ETL design. Meanwhile, the unstructured / semi-structured data needed to be processed in real-time, which could be subscribed to the Apache Kafka and published to the Google Cloud Storage. If the data is structured, it will be processed (ETL) to BigQuery for further analysis.
Once the data is loaded to BigQuery or Cloud Storage, it is easily drawn for data visualization in Microsoft PowerBI and advanced (predictive) analysis in the Python Jupyter Notebook. The predictive result will be loaded back to the BigQuery as a new data shource for future analysis and processing.
For advanced analytics and machine learning, data will be retrieved from BigQuery and being loaded to the Juypter Notebook with calling TensorFlow and other Python libraries for the calculations and analysis. Insights will be shared with their management with dashboards in PowerBI and emails with data attached.
Conclusion
With the rapid changes in the technical world, it is not necessary to bound our design for either purely cloud or purely on-premise. More and more solutions will become hybird with the mixture of cloud and on-premise together.